Identification de versions numériques d'ouvrages physiques à l'aide d'OpenRefine
Il y a peu il m'a été demandé de trouver parmi les ouvrages disponibles en version papier dans notre bibliothèques lesquels étaient aussi disponibles en version électroniques. Dans le meilleur des mondes, les identifiants seraient normalisés et j'aurais accès à une base de données contenant tous mes titres dans laquelle je pourrais faire un SELECT simple pour avoir cette liste. Mais ça ne vaudrait pas le coup d'en faire un billet ici.
Multiplier les identifiants pour augment nos chances de réussite
Le fichier que nous avons extrait de notre SIGB contient pour chaque titre un ISBN qui correspond à une version de l'ISBN de l'ouvrage papier. Le problème est que cet identifiant n'est pas forcément celui dont nous disposons dans les métadonnées des versions numériques du document. Pour augmenter les chances de recouvrement nous allons donc commencer par associer à cet ISBN de base des ISBN réputés équivalents. pour cela nous allons utiliser les deux ISBN suivants : ThingIsbn (de LibraryThing) & xSIBN (d'OCLC), on appelle successivement les deux pour augmenter les chances de ne rien louper mais on pourrait se contenter de l'un ou l'autre.
ThingIsbn
On commence par cette API qui semble a priori non limitée (présentation de 2006) et offre un taux de couverture assez intéressant. Pour cela, sur ma colonne ISBN de base, je vais lancer le processus de création à partir d'URL avec la formule GREL suivante :
"http://www.librarything.com/api/thingISBN/" + value.trim().strip()
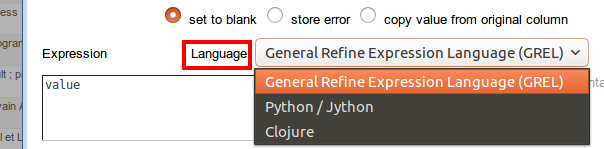 Pour harmoniser le résultat avec ce que me proposera par la suite xISBN, je vais transformer le XML retourné en une chaine séparant les différents ISBN par des # (attention, opération en Jython et non en GREL, dans la popup qui apparaît dans laquelle on saisit l'opération via la liste déroulante reproduite dans l'image ci-contre) :
! On pourrait certainement faire la même chose en GREL mais dans certains cas, et en particulier pour traiter du XML, Jython reste plus intuitif.
Pour harmoniser le résultat avec ce que me proposera par la suite xISBN, je vais transformer le XML retourné en une chaine séparant les différents ISBN par des # (attention, opération en Jython et non en GREL, dans la popup qui apparaît dans laquelle on saisit l'opération via la liste déroulante reproduite dans l'image ci-contre) :
! On pourrait certainement faire la même chose en GREL mais dans certains cas, et en particulier pour traiter du XML, Jython reste plus intuitif.
from xml.etree import ElementTree as ET
element = ET.fromstring(value.encode("utf-8"))
resultsList = element.findall("./isbn")
output = ""
for result in resultsList:
if output != "":
output += "#"
library = result.text
output += "%s" % (library)
return outputxISBN
J'utilise cette API dans un deuxième temps car elle a été annoncée comme "presque" retirée par OCLC en 2015, avant de finalement être maintenue dans l'attente d'une alternative, mais il n'est plus possible d'obtenir un nouveau compte pour l'utiliser. On doit donc se contenter de l'accès public, limité à 1000 requêtes par jour. Avant de lancer l'opération je crée donc une facette pour limiter aux entrées pour lesquelles on n'a rien trouvé via ThingIsbn (pour cela, sur la colonne ThingIsbn : Facet > Customized facet > Facet by blank) afin de limiter le nombre d'appels. À partir de l'ISBN source on crée une colonne à l'aide de la formule suivante :
"http://xisbn.worldcat.org/webservices/xid/isbn/" + value.trim().strip() + "?method=getEditions&format=json"
Pour harmoniser le json récupéré avec ce que l'on a reçu de ThingIsbn, on exécute sur la colonne la formule suivante :
forEach(value.parseJson()["list"],v,v.isbn[0]).join("#")
Cette opération récupère l'ensemble des entrées contenues dans la zone list du json retourné par OCLC (voir en ligne). Pour chacune des valeurs ainsi identifiée (v), on va récupérer le champ isbn qui est un tableau dont on va extraire la première entrée isbn[0]. Toutes ces valeurs sont ensuites concaténées avec un séparateur # via la commande join.
Fusion des deux colonnes
À partir de cette étape, on a donc une colonne thingIsbn et une colonne xIsbn qui contiennent chacune des isbn éventuellement multiples. On va tout basculer dans la colonne thingIsbn avec la méthode suivante :
- On fait une "Facet by blank" sur la colonne thingIsbn;
- On limite l'affichage aux lignes pour lesquels la facette vaut True, donc les lignes avec un thingIsbn vide;
- Sur la colonne thingIsbn, on exécute l'opération Edit cells > Transform
- On saisie comme fonction :
cells["xIsbn"].valuepour faire entrer dans la colonne thingIsbn la valeur de la colonne xIsbn - Les lignes pour lesquelles thingIsbn reste vide sont celles pour lesquelles aucune des deux API n'a répondu. On va donc se contenter d'y copier la valeur de notre ISBN source en appliquant à la colonne via Edit cells > Transform la fonction :
cells["ISBN"].value.replace("-", "")(la colonne contenant mes ISBN source a pour en-tête "ISBN", on en profite pour retirer les - qui ne sont pas présents dans les retours des API précédentes et pas présents dans mon fichier d'ebooks de référence). On prendra bien garde d'avoir limiter la facette aux lignes ayant un thingIsbn à blank avant de faire cette manipulation pour ne pas écraser des résultats d'API.
À partir de là, on se retrouve avec une colonne thingIsbn sur laquelle on peut travailler et qui contient selon les cas un ou plusieurs ISBN, séparés par le signe # dans le cas d'ISBN multiples.
Division des ISBN multiples
Avant de comparer avec notre fichiers de livres électroniques, il est nécessaire de diviser les lignes contenant dans la colonne thingIsbn plusieurs ISBN. Pour cela, sur la colonne concernée, on va appliquer l'opération : Edit cells > split multi-valued cells. Dans la popup qui apparaît, on choisit le séparateur # et on obtient alors un fichier qui ressemble au suivant :
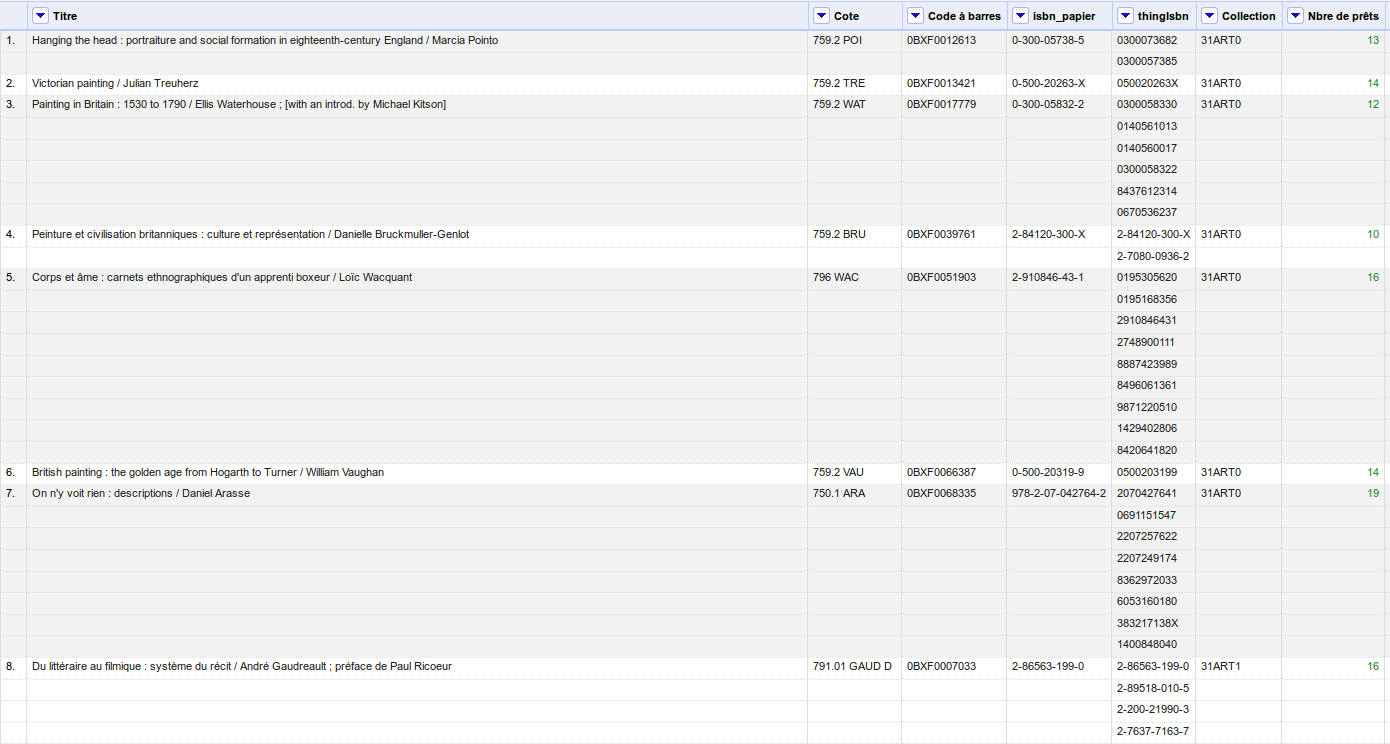
Pour faciliter le travail par la suite, on peut remplir les cellules vides ainsi générées en reprenant les titres, cotes ... correspondant à la notice source. Pour cela, sur chaque colonne on va choisir : Edit cells > Fill down.
Comparaison avec le fichier des ebooks
Une solution que nous utilisons régulièrement est d'appeler notre Opac en lui passant en paramètre l'ISBN et, en parsant la page ainsi récupérée, analyser si le document existe ou pas. Dans le cas où le nombre de notices est important et pour des raisons de performance il peut être intéressant de comparer directement avec un fichier extrait du système. Dans le cas présent nous avons récupérer une extaction de notre fichier ERMS que nous allons comparer au projet OpenRefine que nous avons créé jusqu'ici.
! Pour plus de détails sur la recherche croisée sous OpenRefine, voir l'article vlookup in Google Refine. Ça date de 2011 mais c'est assez détaillé.
Le fichier auquel on souhaite se confronter doit être chargé lui aussi comme un projet OpenRefine. J'ai donc créé un projet "ERMS_ebooks" qui correspont à un fichier CSV issu de mon ERMS et contenant un peu plus de 200 000 lignes (on a déclaré EEBO ça fait vite du volume ...). Une fois ce projet créé, on peut y faire référence dans notre projet principal. Pour cela, on va se rendre sur la colonne ThingIsbn obtenue à la fin du traitement précédent et lancer la manipulation suivante dans Edit columns > Add column based on this column :
cell.cross("ERMS_ebooks", "ISBN10").cells["URL"].value[0]
Cette formule indique l'on souhaite croiser nos données avec le projet ERMS_ebooks, que l'élément en cours (ThingIsbn) doit être comparé à la colonne ISBN10 de ce projet distant. Et que dans le cas où une équivalence est trouvée, on souhaite récupérer l'information qui se trouve dans la colonne URL du projet distant.
Enrichissements locaux
! Les manipulations ci-dessous sont des notes internes à l'Université Bordeaux Montaigne, de peu d'intérêt pour d'autres situations mais laissées ici pour mémoire locale et pour les plus curieux.
Dans le fichier généré ci-dessus, on ne dispose pas du lien direct vers la notice dans Babord+ (notre Opac local en 2018, amené à changer sous peu). Pour faciliter le traitement par les collègues destinataires du fichier, on va donc utiliser la procédure suivante :
- Ajout d'une colonne qui contient l'identifiant dans le système ERMS (
cell.cross("ERMS_ebooks", "ISBN10").cells["Id"].value[0]) - À partir de cette colonne, on va pouvoir récupérer la notice dans Babord+ en construisant une URL qui va interroger l'index contenant cet identifiant de l'ERMS :
"https://babordplus.u-bordeaux.fr/notice.php?q=id_origine:" + value + "&ct=bx3_ws". La notice que l'on récupère utilise le thème bx3_ws créé à cette fin et qui correspond à une notice simplifiée, facilement "parsable" - On va extraire le permalien du code HTML récupéré à l'aide de la commande suivante :
value.parseHtml().select("p.sid-permalink")[0].select('a')[0].htmlAttr("href"). Dans cette manipulation, on sélectionne la première (et seule) balisepayant pour classe sid-permalink et à l'intérieur de celle-ci, on récupère le lien (a) duquel on va extraire (htmlAttr) l'attributhrefqui correspond au permalien vers la notice. - On aurait pu se contenter du lien avec le paramètre id_origine mais l'idée ici est d'être cohérent avec ce qu'on a déjà par ailleurs et d'utiliser le même type de permalien.