Formation documentaire et booléens - Bibliothèques et fake news
Note : ce billet est une traduction / adaptation d'un billet publié par Aaron Tay : The evolving librarian - reconsidering teaching of boolean, CRAAP for fake news and calculating open adjusted cost per use publié le 27 février 2018. Aaron publiant ses articles sous licence CC-BY-NC j'ai décidé de traduire celui-ci en français. Je ne me suis pas interdit certaines adaptations sur la structuration des paragraphes et ma traduction peut avoir modifier certaines précisions apportées par Aaron, considérez donc que les informations ici publiées sont de ma responsabilité, pour connaître l'avis exact d'Aaron je vous renvoie à son article original en anglais.
Ce billet est assez long mais je pense sincèrement que sa lecture est utile (je n'aurais pas pris le temps de le traduire sinon), en plus il y a plein d'images :)
1. Arrêtons de parler d'opérateurs booléens (si l'on n'y est pas forcé)
En 2013, j'ai publié un article intitulé "Pourquoi les recherches booléennes imbriquées ne sont peut-être plus aussi pertinentes qu'avant" qui expliquait pourquoi, à mon avis, les opérateurs booléens étaient devenus peu utiles dans la plupart des situations, et éventuellement contre-productifs dans certains cas (à l'exception de certains contextes exceptionnels tels qu'une revue systématique).
J'y notais que les opérateurs booléens, et en particulier le fait de les imbriquer, lors d'une requête du type (A OR B OR C) AND (D OR E OR F) par exemple était peut-être moins utile que par le passé.
Il y a quelques décennies (années 1990 et début des années 2000), la plupart des recherches dans des bases de données se faisaient dans un environnement contraint :
- bases de données spécialisées, avec une offre transversale limitée;
- des "recherches exactes" principalement, pas ou peu de recherche automatisée sur les formes dérivées d'un mot (stemming);
- pas de recherche dans le texte intégral, les bases étant quasiment toutes des bases bibliographiques;
En raison de ces contraintes, la plupart des recherches ne retournaient que peu de résultats. La recherche en langage naturelle en particulier n'était pas comprise par ces outils qui la comprenait comme une recherche booléenne stricte sur les métadonnées et ne retournait en général aucun résultat. Les opérateurs booléens permettaient de pallier ces contraintes de recherche en limitant les termes de la requête aux mots "critiques" de la recheche et de gérer les synonymes à l'aide de OR.
Mais que sont devenues ces contraintes aujourd'hui ? L'environnement qui nous entoure est principalement composé de bases de données massives, accompagnées de Google Scholar et d'outils de découvertes. On peut ainsi faire des recherches multi-disciplinaires, de l'interrogation en texte intégral, et compter sur des systèmes qui vont faire des recherches sur toutes les formes d'un mot pour s'assurer qu'on ne loupera pas une variante.
S'ajoute à cela une baisse chronique de l'usage des opérateurs booléens qui n'incite pas les fournisseurs de service à optimiser leurs algorithmes de pertinence pour les réponses apportées à ce type de requêtes.
Dans mon billet de 2014 je donnais mon avis sur le sujet mais en me limitant à un ou deux exemples et je n'avais pas connaissance d'étude poussée sur le sujet.
Dans l'article "The Boolean is Dead, Long Live the Boolean! Natural Language versus Boolean Searching in Introductory Undergraduate Instruction" (actuellement en preprint), les auteurs ont testé l'efficacité de différents types de recherches.
À partir d'un ensemble de requêtes sur des sujets variés, ils ont interrogé les plateformes suivantes :
- Academic Search Premier
- Google Scholar
- JSTOR
- Lexis Nexis
- Proquest
- Pubmed
- Scopus
- Web of Science
Voici un exemple de requêtes testées en fonction des sources :
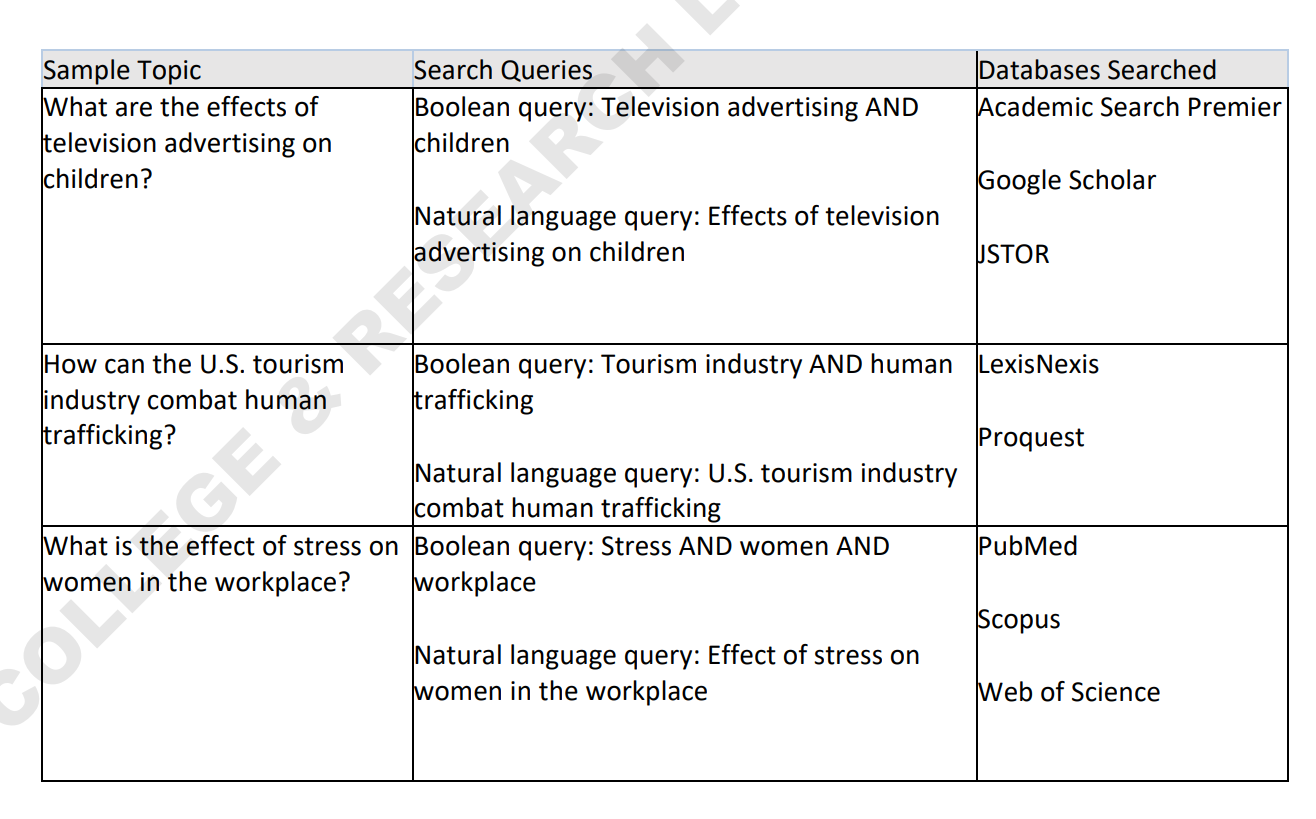
On peut voir dans cet extrait de l'article qu'ils ont par exemple analysé les réponses d'Academic Search Premier, Google Scholar et Jstor sur la requête "Television advertising AND children" et l'ont comparé à une requête "Effects of television advertising on children".
Ils ont aussi analysé l'effet de différents filtres sur les résultats de recherche : "peer reviewed" (Proquest Central), "Articles" (JSTOR / Scopus / Web of Science).
Pour chacune de ces recherches, ils ont récupéré les 25 premiers résultats et ont construit à partir de cette liste un indicateur de pertinence.
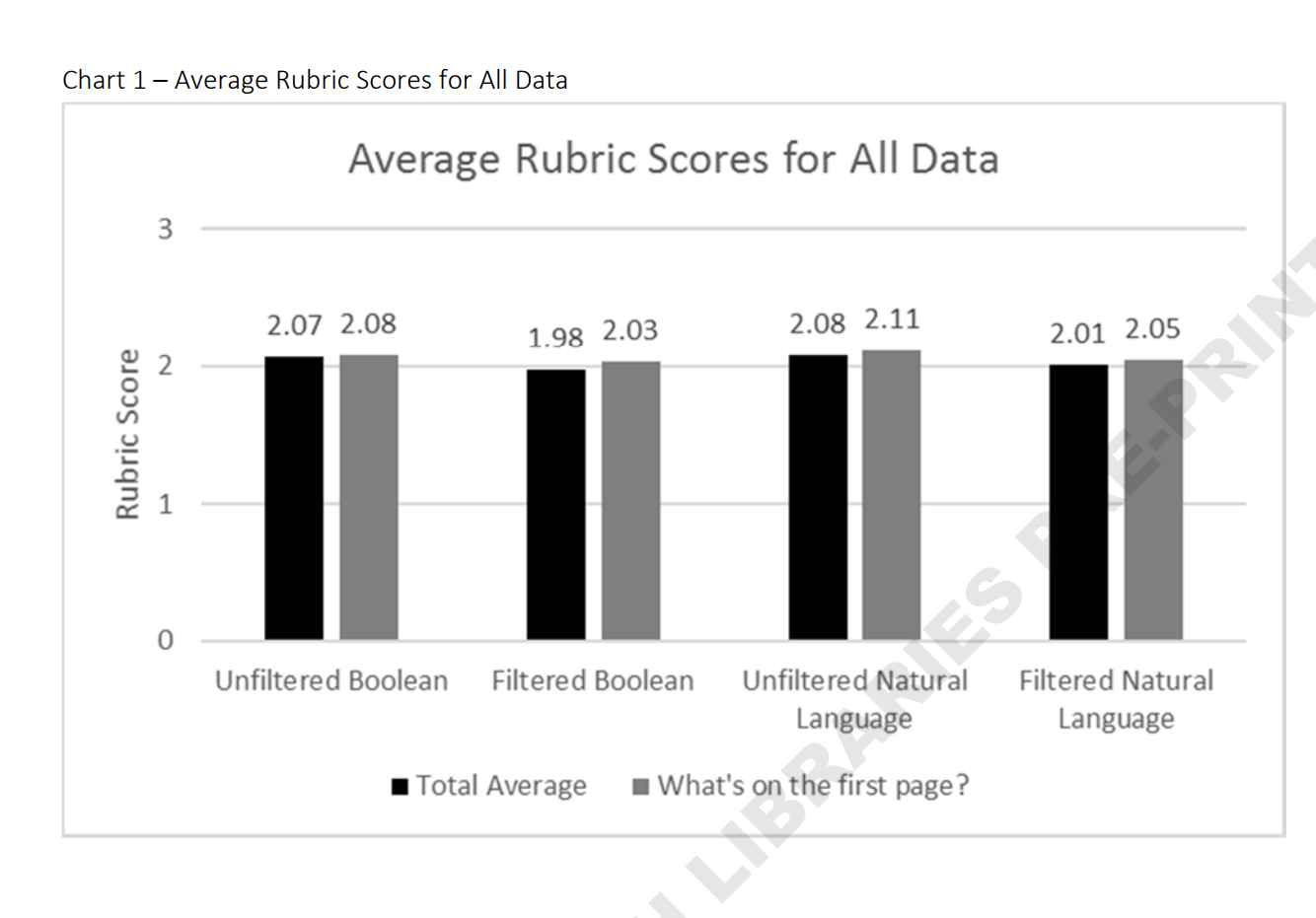
Et devinez quoi ? Même si les requêtes en langue naturelle retournent moins de résultats, c'est ces requêtes en langage naturel non filtrées qui obtiennent, en moyenne et pour le top 25 des réponses, le meilleur indicateur ! Et les requêtes avec opérateur booléen et filtre ont le moins bon score. Pour être tout à fait honnête, la différence de score est relativement faible (2,11 contre 2,08 entre langage naturel et booléens pour le top 25 non filtré) et il est difficile d'en tirer une généralité. Mais cela reste un résultat intéressant.
Il est intéressant de noter, contrairement à ce que j'aurais pressenti, que le résultat est aussi valable pour les bases de données bibliographiques comme Web of Science, Scopus ou Pubmed. Même si encore une fois, les requêtes utilisées sont assez généralistes et qu'il n'est pas forcément possible d'en tirer des conclusions définitives, cela interroge.
Je recommande vivement la lecture de l'article complet ou si vous avez la flemme, mon résumé en 6 tweets.
Le point principal à retenir reste que les requêtes en langage naturel ont l'air de ne pas être plus mauvaises que des requêtes avec opérateurs booléens, en tout pas pour les requêtes et les bases testées. Et les auteurs de conclure :
Cette étude n'a pas permis d'identifier d'avantage clair entre les requêtes en langage naturel et celles basées sur les opérateurs booléens, ce qui nous conduit à suggérer que les formateurs pour les cours d'initiation à la recherche documentaire, peuvent diminuer le temps consacré aux aspects techniques de la recherche documentaire, et consacrer le temps libéré à des sujets plus génériques de la littératie, sur la manière de définir son sujet, évaluer les sources ...
D'autres pistes d'étude ?
Faisons attention à ne pas surinterpréter le résultat de cette étude. Elle se contente de tester l'opérateur AND sur un petit échantillon de requête, mais les résultats sont évocateurs, à défaut d'être conclusifs.
L'étude se contente de comparer langage naturel et concepts-clés enchainés avec l'opérateur booléen AND, et ne traite pas le sujet de mon billet initial à savoir l'inutilité des opérateurs booléens imbriqués.
Il y a globalement trois types de requêtes que je vois passer dans les logs de nos outils :
- des requêtes en langage naturel : "What is the effect of television advertising on children"
- des booléens simples : "television advertising AND children"
- des booléens imbriqués : "(Television OR TV) AND (Children OR Child OR Youth OR Kid)"
Non je mens, je ne vois jamais le #3 ou alors c'est des bibliothécaires qui en sont à l'origine. Et malgré cela, beaucoup de bibliothécaires ont dans le passé (et peut-être encore ?) enseigné le #3.
Je suis convaincu que le #2, dans la majorité des cas, ne sera pas moins bon que le #3. J'avoue être légèrement surpris que #1 ne soit pas plus mauvais que #2 mais je suspecte que ça devient le cas dès lors que l'on arrive sur des requêtes qui retournent beaucoup moins de résultats que la publicité et les enfants.
Une suite intéressante que j'imagine serait de répéter l'étude avec des requêtes booléennes imbriquées plus compliquées, et sur des sujets plus complexes, où le nombre potentiel de résultats est plus limité que sur une requête généraliste.
Je serais en particulier curieux de voir si les requêtes booléennes imbriquées avec des OR se détacheraient pour des bases de données bibliographiques telles que Scopus, Web of Science et Pubmed. Il me semble que la littérature concernant les revues systématiques dans le domaine médicale penche en ce sens, mais on peut considérer que Pubmed n'est pas une base de données classique.
Dans la vraie vie et à titre personnel, je continuerai à déconseiller la recherche en langage naturel à mes étudiants (#1) et leur conseillerai d'utiliser seulement des mots-clés (#2), mais j'éviterais de laisser croire que les requêtes booléennes imbriquées sont nécessairement meilleures.
2. Teaching of CRAAP and list based methods to combat fake news
Comme d'habitude je tiens à rappeler que je ne suis pas expert en littératie mais la lecture récente de trois articles m'a conduit à réfléchir à CRAAP et ses objectifs, et je synthétise ici mais réflexions à ce sujet, pour discussion (Ndt : ce paragraphe en italique est présent dans l'article original).
L'actualité récente autour des fake news a conduit les bibliothécaires que nous sommes à clamer haut et fort l'intérêt des formations documentaires que nous effectuons, et l'importance de notre expertise dans ce domaine. Et les bibliothécaires de s'empresser de critiquer tout articles évoquant la littératie en oubliant de mentionner le rôle des professionnels que nous sommes.
This #fakenews article is what has lots of #librarians saying "this is what we we're trying to tell you all along" https://t.co/NOgX2bZT4b
— steven bell (@blendedlib) December 12, 2016
Car après tout, il semble que ce soit un de nos super-pouvoirs.
We all know that librarians are superheroes. The latest villain they've been fighting is fake news. https://t.co/31Giwdzgxv
— The Harry Potter Alliance (@TheHPAlliance) January 3, 2017
En dehors des sources bibliothéco-centrées, des articles ont commencé à apparaître dans les médias grand publics, tels the Salon, U.S. News & World report et PBS, soulignant le rôle que les bibliothécaires pouvaient jouer pour contrer la montée des fake news. De nombreux bibliothécaires se sont extasiés, notre heure était venue !
Je n'ai aucun doute que les bibliothécaires ont un rôle à jouer, mais je me demande souvent à quel point notre rôle est important, et comment le remplir au mieux.
De ce que je vois, la première chose que de nombreux bibliothécaires ont fait a été de créer des libguides sur le sujet des fake news. Et bien sûr, la plupart d'entre nous sommes conscients que l'impact que cela peut avoir est minimal.
"Before I read this thing my friend posted on Facebook, let me open up that helpful LibGuide in another tab." <--No Student Ever
— Lane Wilkinson (@lnwlk) January 24, 2017
Mais ce que nous enseignons quand nous faisons de la littératie dans les formations à la recheche documentaire n'est pas déjà une bonne solution pour lutter contre ce problème. Et comment utiliser au mieux ces sessions en ce sens ? Il existe au moins une chose que nous présentons déjà et qui va dans ce sens : le test CRAAP (Ndt : pas forcément présenté en France sous cet acronyme, mais présenté sous d'autres formes).
Si vous êtes bibliothécaire vous en avez sûrement entendu parler. Sinon, c'est un test qui nous vient de la Meriam Library de l'Université d'État de Californie à Chico et qui recommande aux utilisateurs d'évaluer une ressource à l'aide de la méthode CRAAP qui correspond aux initiales de :
- Currency : actualité de l'information
- Relevance : l'information correspond-elle à ce dont vous avez besoin
- Authority : réputation de l'auteur
- Accuracy : exactitude de l'information
- Purpose : raison d'exister de cette information
Je ne suis pas capable de remonter l'origine de CRAAP mais la wayback machine suggère que l'acronyme est apparu sur la page de la bibliothèque en 2001, bien que des critères similaires apparaissent dans des versions antérieures.
Il existe d'autres systèmes d'évaluation basés sur des listes, mais grâce à son nom facile à retenir (Ndt: et proche de l'argot anglais crap qui désigne quelque chose de mauvaise qualité ?) CRAAP est celui qui a rencontré le plus de succès. Mon intuition est que ces listes destinées à évaluer des ressources sont devenues populaires au début des années 1990, lorsque l'on est passée d'une information rare à une phase d'abondance.
Étant donné que CRAAP date de la fin des années 1990, début des années 2000, il est naturel de se demander s'il ne serait pas temps de l'adapter pour répondre à la problématique actuelle des fake news ? Est-ce que ce n'est pas juste le même problème que précédemment présenté différemment ?
L'étude Stanford
Commençons par nous intéresser à un test empirique sur la capacité qu'ont les internautes à identifier des sites fiables. Dans l'étude "Lateral Reading: Reading Less and Learning More When Evaluating Digital Information", on a demandé à un groupe de 45 personnes comprenant 10 historiens, 10 "fact checkers" professionnels et 25 étudiants de premier cycle de Stanford d'évaluer quelques sites web en leur laissant toute liberté dans la recherche d'information.
Une des questions posées était liée à l'évaluation de rapports sur le thème "harcèlement scolaire" à partir des deux sites suivants :
- https://www.acpeds.org/the-college-speaks/position-statements/societal-issues/bullying-at-school-never-acceptable
- https://www.aap.org/en-us/about-the-aap/aap-press-room/pages/Stigma-At-the-Root-of-Ostracism-and-Bullying.aspx
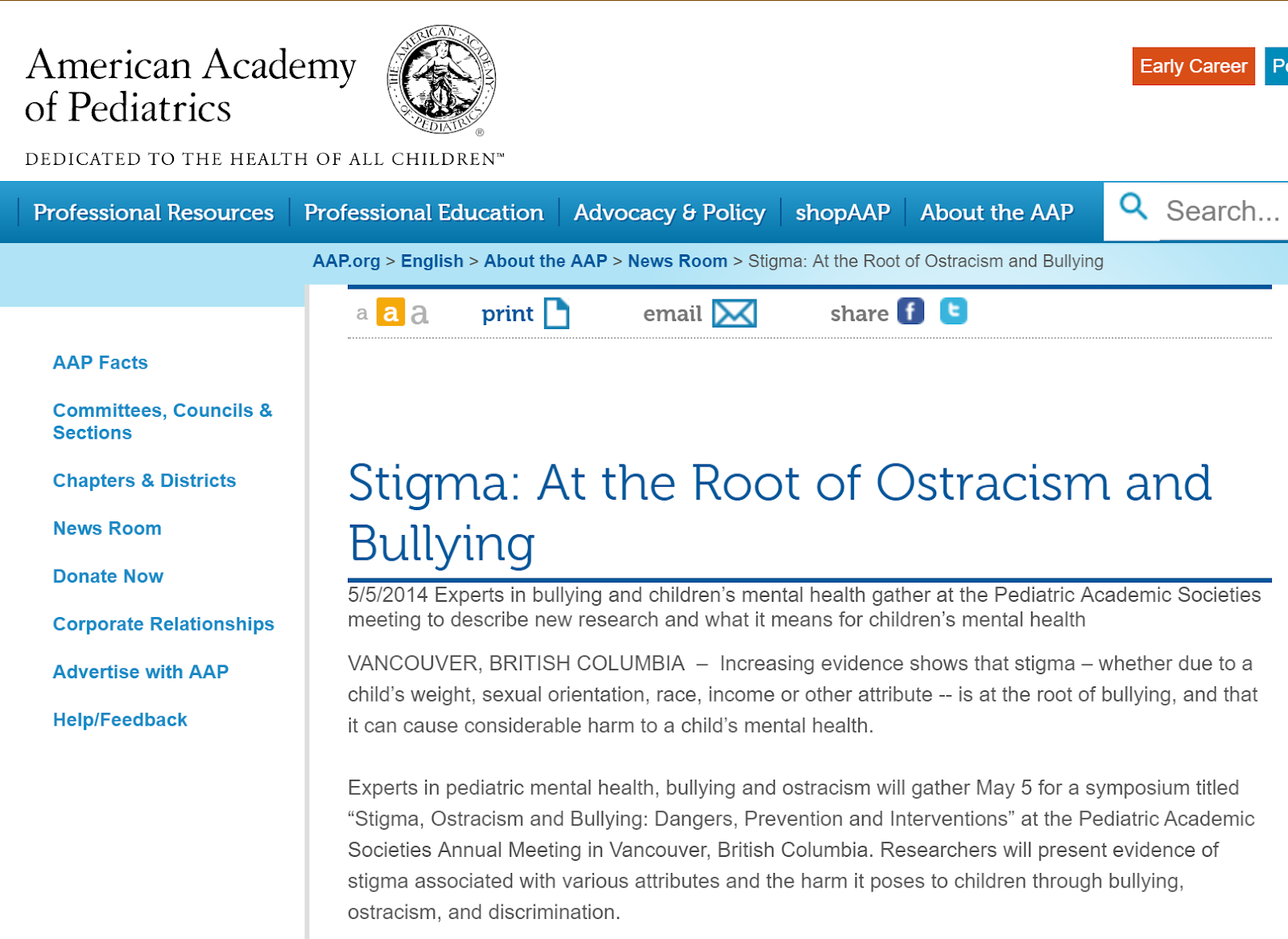
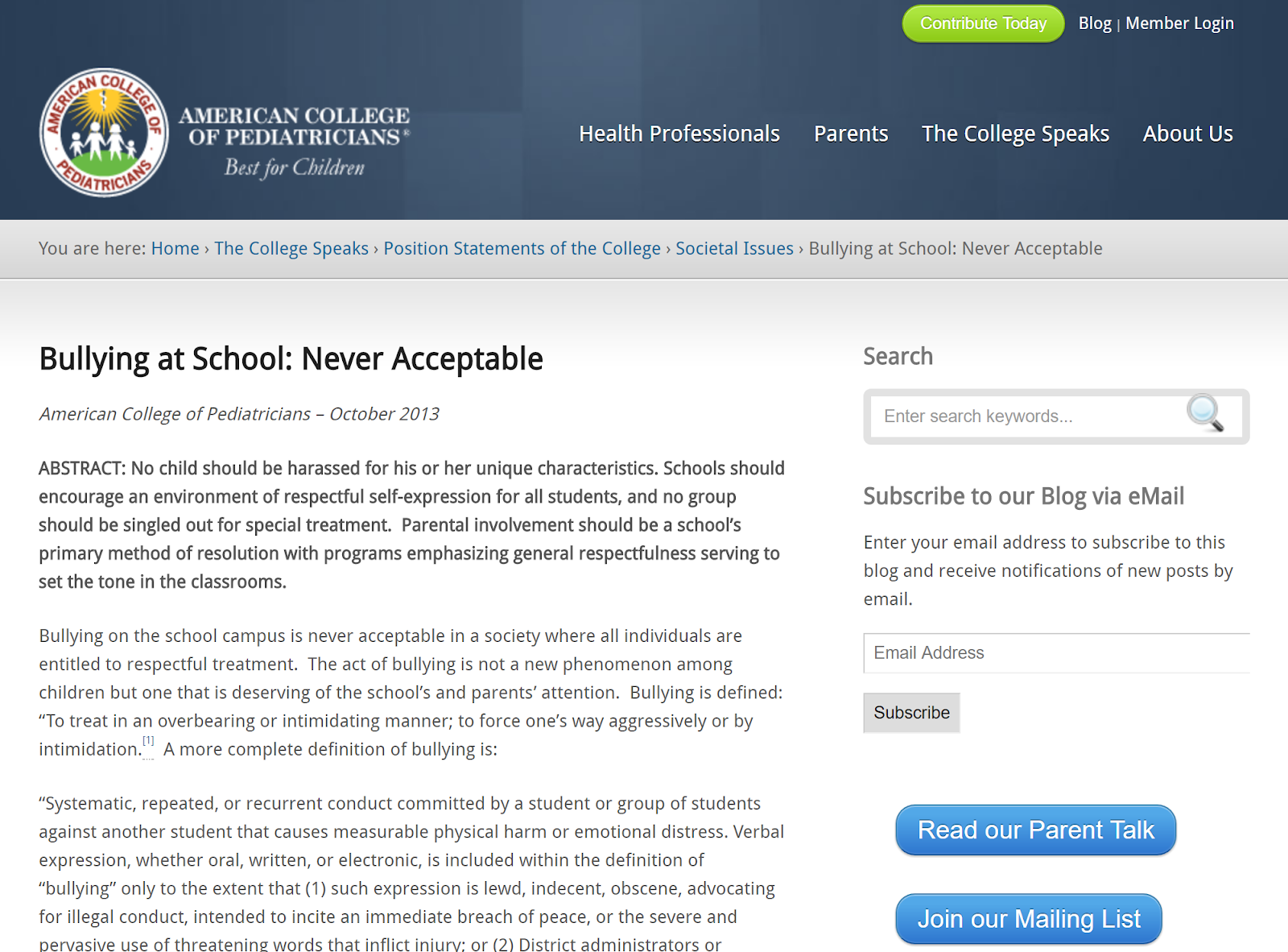
Pour cette question, l'un des rapports émanait de l'American Academy of Pediatrics (“the Academy”) et l'autre de l'American College of Pediatricians (“the College”). Lequel de ces sites web est le plus fiable ?
À première vue, les deux semblent assez fiables mais (car il y a un mais), seul le premier l'est vraiment. "The academy" est la plus importante organisation professionelle de pédiatres au monde, éditrice de la revue phare de la profession. La seconde, "the college", est un groupe ayant fait sécession de "the academy' lors de débats sur l'adoption par les couples LGBT ayant eu lieu en 2002. Cette seconde organisation compte seulement quelques centaine de membres (entre 200 et 500), un salarié et ne publie pas de journal.
Comment historiens, fact checkers et étudiants ont analysé la situation ?
Fact checkers vs. Historiens vs. Étudiants
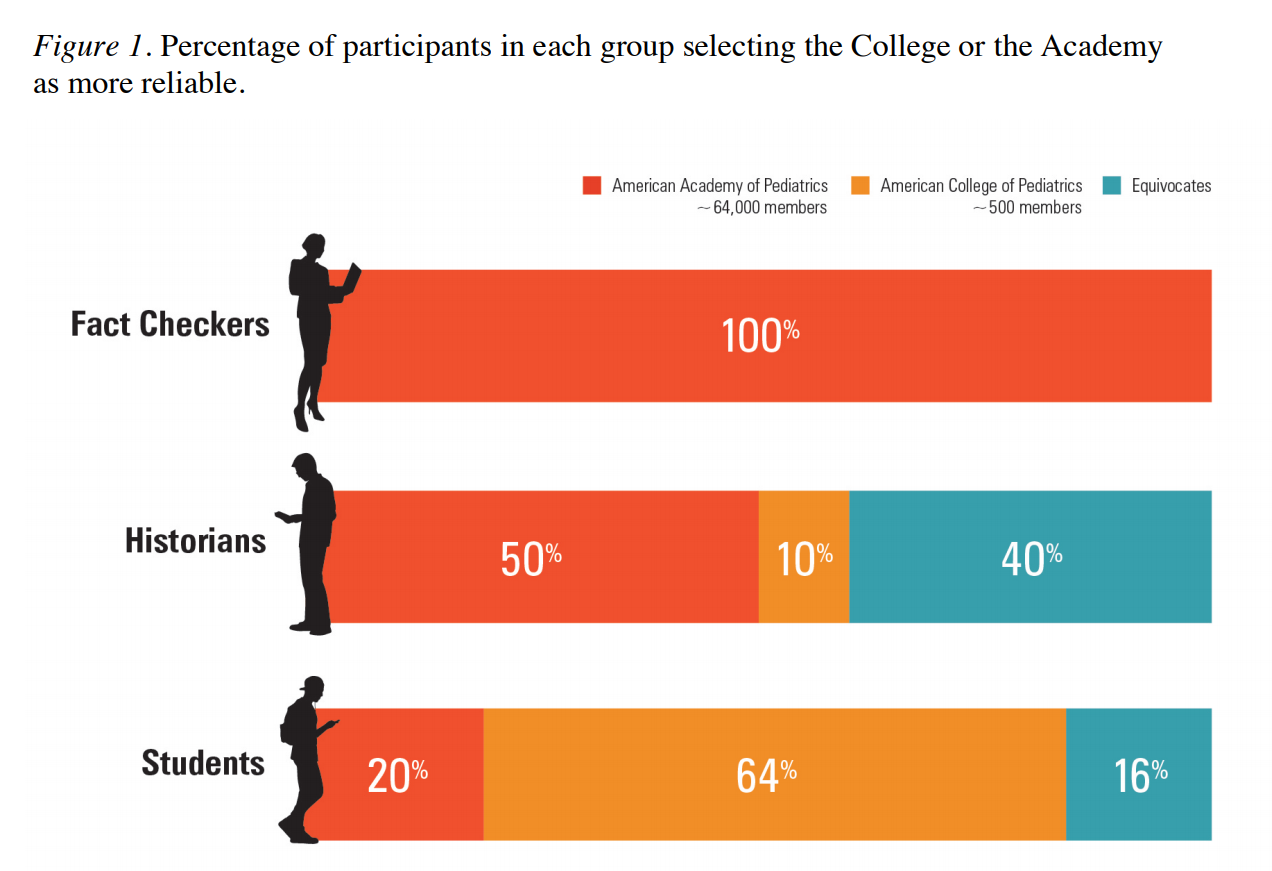
Le résultats est étonnant. Malgré leur expérience et leurs connaissances, la moitiers des historiens se sont fait avoir. 40% d'entre eux n'ont pas identifié de différence de fiabilité entre les deux sites, et 10% ont même pensé que "the College" était plus pertinent. Ils ont tout de même fait mieux que les étudiants de premier cycle, mais bien pire que les fact checkers qui ont tous identifié le site le plus fiable.
Je ne vais pas reprendre les deux autres expériences relatées dans cette étude mais les résultats sont similaires. Les fact checkers sont passées à travers les pièges, alors que les historiens et les étudiants ont eu plus de mal.
Pourquoi ? Encore une fois, je ne vais pas résumer toute la publication et je vous invite à la lire, car elle donne des détails passionnants sur la manière dont les fact-checkers pensent et cherchent différemment des autres groupes. Mais le résultat est que les fact-checkers font très rapidement des recherches croisées d'informations sur des sites tiers.
L'article appelle cela "Taking bearings" (Ndt: qu'on pourrait traduire par "prendre ses marques" ?). Alors que les historiens et étudiants passent du temps à analyser la page qu'on leur présente, les fact-checkers vont rapidement sur d'autres sites pour en apprendre plus sur la page qu'on leur a demandé d'étudier.
Par exemple, l'étude explique qu'un des fact-checkers a passé 8 secondes sur les pages test avant d'aller sur Google pour chercher des informations sur le producteur de chacun des deux sites. Ce qui lui a rapidement permis de connaître l'histoire à l'origine de chacune des ces deux organisations.

En comparaison, seulement deux des historiens ont adopté cette méthode. La plupart ont passé beaucoup de temps (quand ce n'est pas l'ensemble des 10 minutes imparties) sur les sites web à analyser. Et ils ont souvent été trompés, pour "the College" par le terme "College" dans le nom de l'organisation, le logo, le domaine en .org, l'esthétique générale du site web et son apparance scientifique, les résumés de la publication, les notes de bas de page et le fait que les articles soient signés par des docteurs.
Est-ce que les bibliothécaires auraient fait mieux ? Est-ce que CRAAP aurait aidé ?
On pourrait se demander si le résultat aurait été différent si l'on avait soumis le test à des bibliothécaires. Auraient-il fait mieux en appliquant CRAAP ou toute autre méthode d'évaluation basée sur une checklist ?
Voyons pour CRAAP. Si l'on observe que les historiens se sont fait bernés par le logo et le domaine en .org, on peut s'imaginer que les étudiants cherchant à analyser l'authority des articles, auraient fait la même erreur. Et si l'on regarde plus en détail CRAAP, la plupart des points impliquent seulement d'analyser la source que l'on souhaite évaluer :
- y a-t-il des fautes d'orthographe, de grammaire ou typographiques ?
- est-ce que l'expression a l'air neutre ?
- y a-t-il des informations de contact, un éditeur ?
- est-ce que l'URL donne une indication sur l'auteur ? Par exemple .com .edu .gov .org
Certains points de CRAAP orientent vers les bonnes questions mais n'imposent pas assez à l'auteur d'aller croiser ses sources :
- qui est l'auteur / éditeur / source / financeur ?
- quelles sont les affiliations de l'auteur ? son statut ?
On peut en effet imaginer que pour beaucoup d'utilisateurs, la réponse à ces questions passera pas la lecture des informations présentes dans la source elle-même. "Humm, la biographie de l'auteur indique qu'il est professeur à Harvard, l'information est donc sérieuse".
Si l'on continue dans les questions proposées par CRAAP, on en trouve plusieurs qui semblent surtout là pour permettre au lecteur de décider si l'information peut lui être utile. On voit ici un des usages de CRAAP qui est de choisir les sources à citer dans un rendu universitaire j'imagine :
- est-ce que votre sujet nécessite de se baser sur des informations récentes, ou bien des sources anciennes peuvent elles être intéressantes ?
- est-ce que l'information est liée à votre sujet ou répond à votre question ?
- est-ce le niveau intellectuel de l'information est adapté (pas trop simple ou trop avancée par rapport à vos besoin) ?
- est-ce que vous seriez prêt à citer cette source dans vos travaux de recherche ?
Et enfin certaines des questions sont totalement subjectives, sans qu'aucun guide ne permette de savoir comment répondre :
- est-ce que l'auteur est qualifié pour écrire sur ce sujet ?
- à quelle audience est destiné le contenu ?
On peut se dire que CRAAP a été créé à une époque où la ligne entre une information fiable et une moins fiable était plus claire. Par exemple les blogs étaient quasiment tout le temps moins fiable qu'un site gouvernemental (gov) ou universitaire (edu), il était à peu près toujours possible de dire rapidement si l'on avait à faire à un éditeur universitaire (par opposition à la situation actuelle où l'on rencontre des journaux prédateurs et des blogs tenus par des spécialistes).
Un des problèmes principaux de CRAAP est qu'il est justement destiné, pour résumer, à faire la disctinction entre un blog et un journal scientifique. Il n'est pas très adapté à des sources dont la volonté est de tromper le lecteur. De nombreux signaux du questionnaire CRAAP peuvent facilement être contournés si l'on se limite à la source elle-même. Les sources principales de fake news qui sont apparues ces dernières années font tout pour apparaître "respectables"*. On se trouve face à des sites web qui ont l'air sérieux, qui semblent émaner de groupes de réflexions respectacles (n'importe qui peut s'acheter un .org de nos jours) et s'évertuent à masquer leur activité de lobbying, ou essaient de se faire passer pour des éditeurs universitaires.
La principale solution pour lutter contre cela est de faire du cross-checking en sortant de la source à analyser. Mais cela prend du temps et j'imagine que la plupart des lecteurs se contenteront des contrôles de base (analyser l'url, l'orthographe et les qualifications des auteurs données par la source).
Il me semble qu'en regard des fake news, l'infographie publiée récemment par l'IFLA est plus pertinente. Les astuces proposées sont plus explicites et mentionnent spécifiquement la nécessité de faire des recherches externes sur les auteurs par exemple.

Un autre problème de CRAAP : l'absence d'une stratégie d'évaluation
Certains bibliothécaires me diront que mon analyse est biaisée et que CRAAP propose de croiser ses sources. Et en effet, on trouve quelques points tels que "pouvez-vous confirmer l'information par vos connaissances personnelles ou une recherche dans une source externe ?", mais ces points sont noyés dans une longue checklist. Et c'est l'un des points faibles de ces listes, elle ne donne pas à l'utilisateur une méthode d'analyse.
Mike Caulfied, dans son article Recognition Is Futile: Why Checklist Approaches to Information Literacy Fail and What To Do About It dénonce la méthode “E.S.C.A.P.E. Junk News” (une cousine de CRAAP) en faisant le même constat. Pour lui, le problème n'est pas seulement que ces méthodes ne vous incitent pas assez rapidement à quitter la page pour prendre de la hauteur sur l'article, mais qu'elles échouent à commencer par les questions centrales et distraient l'usager avec des points de détails qui, même s'ils peuvent être utiles à l'analyse d'un document, n'en sont pas critiques. Les méthodes types CRAAP posent trop de questions et ne guident pas assez le lecteur.
Il fait un parallèle intéressant avec les médecins. Ceux-ci ne vont pas vous poser des questions aléatoires ou lister tous les symtomes possibles, mais sont formés pour identifier votre problèmes en posant des questions sont la forme d'un arbre de décision qui va permettre de restreindre les possibilités.
Et il donne une méthodologie simple :
- chercher une analyse de l'information : une information publiée sur le web pourra avoir été analysée par une source tierce (Ndt : les décodeurs du Monde, checknews ...)
- remonter la source : si personne n'a analysé l'information, chercher l'origine de l'information relatée dans l'article que vous souhaitez évaluer, une publication antérieure d'où serait dérivé l'article que vous êtes en train d'évaluer. Si vous remontez à une source que vous considérez comme crédible, c'est gagné.
- faire une lecture périphérique (Ndt: Read laterally dans l'article original) : si aucun des points précédents n'a fonctionné, faites une lecture des éléments entourant l'article pour analyser la fiabilité de l'article en croisant avec des sources externes
- revenir au début : il se peut qu'arrivant ici on n'ait pas réussi à répondre à la question de la fiabilité d'une source. Malgré cela on aura forcément appris des choses sur le sujet. Avec ces nouvelles informations portées à notre connaissance, revenir au point 1 et refaire les étapes en changeant sa lecture des informations ou en utilisant des mots-clés de recherche auxquels l'on n'aurait pas pensé en première instance.
On notera qu'il ne donne pas une liste de choses à vérifier sur un article mais plutôt l'ordre dans lequel faire les vérifications.
Biais cognitifs
Dans ce dernier paragraphe, Aaron analyse le billet de blog de Lane Wilkinson : "Teaching Popular Source Evaluation in an Era of Fake News, Post-Truth, and Confirmation Bias". Cette traduction étant déjà bien longue je vous renvoie directement à l'article originale ou à son analyse par Aaron si vous souhaitez en savoir plus.
3. Coût d'usage des ressources et Open Access
Dans cette troisième section de son billet, Aaron réfléchit à l'étude du coût d'usage dans un monde où l'Open Access (green en particulier) se développe, je ne le traduirai pas ici mais là encore, vous incite à aller lire l'original si vous le pouvez
Traduction effectée début mars 2018, publiée le 8 mars.